| Concept: Test-Ideas Catalog |
 |
|
| Related Elements |
|---|
IntroductionMuch of programming involves taking things you've used over and over before, and then using them yet again in a different context. Those things are typically of certain classes-data structures (such as linked lists, hash tables, or relational databases) or operations (such as searching, sorting, creating temporary files, or popping up a browser window). For example, two customer relational databases will have many clichéd characteristics. The interesting thing about these clichés is that they have clichéd faults. People do not invent imaginative new ways to insert something incorrectly into a doubly-linked list. They tend to make the same mistakes that they and others have made before. A programmer who pops up a browser window might make one of these clichéd mistakes:
Since faults are clichéd, so are the test ideas that can find them. Put these test ideas in your test-idea catalog so you can reuse them. How a Test-Ideas Catalog Finds FaultsOne of the virtues of a catalog is that a single test idea can be useful for finding more than one underlying fault. Here's an example of one idea that finds two faults. The first fault was in a C compiler. This compiler took command-line options like "-table" or "-trace" or "-nolink". The options could be abbreviated to their smallest unique form. For example, "-ta" was as good as "-table". However, "-t" was not allowed, because it was ambiguous: it could mean either "-table" or "-trace". Internally, the command-line options were stored in a table like this:
When an option was encountered on the command line, it was looked up in the table. It matched if it was the prefix of any table entry; that is, "-t" matched "-table". After one match was found, the rest of the table was searched for another match. Another match would be an error, because it would indicate ambiguity. The code that did the searching looked like this:
Do you see the problem? It's fairly subtle. The problem is the break statement. It's intended to break out of the outermost enclosing loop when a duplicate match is found, but it really breaks out of the inner one. That has the same effect as not finding a second match: the index of the first match is returned. Notice that this fault can only be found if the option being sought for matches twice in the table, as "-t" would. Now let's look at a second, completely different fault. The code takes a string. It is supposed to replace the last '=' in the string with a '+'. If there is no '=', nothing is done. The code uses the standard C library routine strchr to find the location of '='. Here's the code:
This problem here is also somewhat subtle. The function strchr returns the first match in the string, not the last. The correct function is strrchr. The problem was most likely a typographical error. (Actually, the deep underlying problem is that it's definitely unwise to put two functions that differ only by a typo into a standard library.) This fault can only be found when there are two or more equal signs in the input. That is:
What's interesting and useful here is that we have two faults with completely different root causes (typographical error, misunderstanding of a C construct) and different manifestations in the code (wrong function called, misuse of break statement) that can be found by the same test idea (search for something that occurs twice). A Good Test-Ideas CatalogWhat makes a good catalog?
Given these rules, it seems best to have more than one catalog. Some data and operations are common to all programming, so their test ideas can be put into a catalog that all programmers can use. Others are specific to a particular domain, so test ideas for them can be put into a catalog of domain-specific test ideas. A sample catalog (tstids_short-catalog.pdf) (Get Adobe Reader), used in the following example, is a good one from which to begin. Test Ideas for Mixtures of ANDs and ORs provides another example. An Example of Using a Test-Ideas CatalogHere's how you might use the sample catalog (tstids_short-catalog.pdf) (Get Acrobat Reader). Suppose you're implementing this method:
applyToCommonFiles takes two directories as arguments. When a file in the first directory has the same name as a file in the second, applyToCommonFiles performs some operation on that pair of files. It descends subdirectories. The method for using the catalog is to scan through it looking for major headings that match your situation. Consider the test ideas under each heading to see if they are relevant, and then write those that are relevant into a Test-Ideas List. Note: This step-by-step description might make using the catalog seem laborious. It takes longer to read about creating the checklist than it does to actually create one. So, in the case of applyToCommonFiles, you might apply the catalog in the manner described throughout the rest of this section. The first entry is for Any Object. Could any of the arguments be null pointers? This is a matter of the contract between applyToCommonFiles and its callers. The contract could be that the callers will not pass in a null pointer. If they do, you can't rely on th expected behavior: applyToCommonFiles could perform any action. In such a case, no test is appropriate, since nothing applyToCommonFiles does can be wrong. If, however, applyToCommonFiles is required to check for null pointers, the test idea would be useful. Let's assume the latter, which gives us this starting Test-Ideas List:
The next catalog entry is Strings. The names of the files are strings, and they're compared to see if they match. The idea of testing with the empty string ("") doesn't seem useful. Presumably some standard string comparison routines will be used, and they will handle empty strings correctly. But wait... If there are strings being compared, what about case? Suppose d1 contains a file named "File" and d2 contains a file named "file". Should those files match? On UNIX, clearly not. On Microsoft® Windows®, they almost certainly should. That's another test idea:
Notice that this test idea didn't come directly from the catalog. However, the catalog drew our attention to a particular aspect of the program (file names as strings), and our creativity gave us an additional idea. It's important not to use the catalog too narrowly-use it as a brainstorming technique, a way of inspiring new ideas. The next entry is Collections. A directory is a collection of files. Many programs that handle collections fail on the empty collection. A few that handle the empty collection, or collections with many elements, fail on collections with exactly one element. So these ideas are useful:
The next idea is to use a collection of the maximum possible size. This is useful because programs like applyToCommonFiles are often tested with trivial little directories. Then some user comes along and applies them to two huge directory trees with thousands of files in them, only to discover that the program is grotesquely memory inefficient and can't handle that realistic case. Now, testing the absolute maximum size for a directory is not important; it only needs to be as large as a user might try. However, at the very least, there should be some test with more than three files in a directory:
The final test idea (duplicate elements) doesn't apply to directories of files. That is, if you have a directory with two files that have the same name, you have a problem independent of applyToCommonFiles-your file system is corrupt. The next catalog entry is Searching. Those ideas can be translated into applyToCommonFiles terms like this:
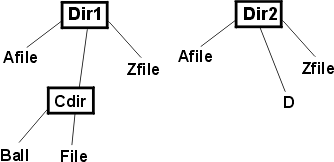
The final test idea checks whether applyToCommonFiles terminates too soon. Does it return as soon as it finds the first match? The parenthetical remark in the test idea before that assumes that the program will fetch the list of files in a directory using some library routine that returns them, sorted alphabetically. If not, it might be better to find out what the last one really is (the most recently created?) and make that be the match. Before you devote a lot of time to finding out how files are ordered, though, ask yourself how likely it is that putting the matching element last will make finding defects easier. Putting an element last in a collection is more useful if the code explicitly steps through the collection using an index. If it's using an iterator, it's extremely unlikely that the order matters. Let's look at one more entry in the sample catalog. The Linked structures entry reminds us that we're comparing directory trees, not just flat collections of files. It would be sad if applyToCommonFiles worked only in the top-level directories, but not in the lower-level ones. Deciding how to test whether applyToCommonFiles works in lower-level directories forces us to confront the incompleteness of its description. First, when does applyToCommonFiles descend into subdirectories? If the directory structure looks like this
Figure 1: A directory structure does applyToCommonFiles descend into Cdir? That doesn't seem to make sense. There can be no match with anything in the other directory tree. In fact, it seems as if files in subdirectories can only match if the subdirectory names match. That is, suppose we have this directory structure:
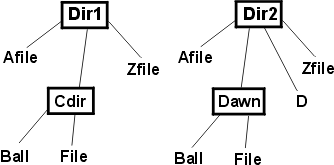
Figure 2: A second directory structure The files named "File" don't match because they're in different subdirectories The subdirectories should be descended only if they have the same name in both d1 and d2. That leads to these test ideas:
But that raises other questions. Should the operation (op) be applied to matching subdirectories or just to matching files? If it's applied to the subdirectories, should it be applied before the descent or afterward? That makes a difference if, for example, the operation deletes the matching file or directory. For that matter, should the operation be allowed to modify the directory structure? And more specifically: what's the correct behavior of applyToCommonFiles if it does? (This is the same issue that comes up with iterators.) These sorts of questions typically arise when you carefully read a method's description of creating test ideas. But let's leave them aside for now. Whatever the answers are, there will have to be test ideas for them-test ideas that check whether the code correctly implements the answers. Let's return to the catalog. We still haven't considered all of its test ideas. The first one-empty (nothing in structure)-asks for an empty directory. We've already got that from the Collections entry. We've also got the minimal non-empty structure, which is a directory with a single element. This sort of redundancy is not uncommon, but it's easy to ignore. What about a circular structure? Directory structures can't be circular-a directory can't be within one of its descendants or within itself... or can it? What about shortcuts (on Windows) or symbolic links (on UNIX)? If there's a shortcut in d1's directory tree that points back to d1, should applyToCommonFiles keep descending forever? The answer could lead to one or more new test ideas:
Depending on the correct behavior, there may be more test ideas than that. Finally, what about depth greater than one? Earlier test ideas will ensure that we test descending into one level of subdirectory, but we should check that applyToCommonFiles keeps descending:
Creating and Maintaining Your Own Test-Ideas CatalogAs mentioned previously, the generic catalog won't contain all of the test ideas you need. But domain-specific catalogs haven't been published outside of the companies that created them. If you want them, you'll need to build them. Here's some advice.
|
| Copyright (c) 2002, 2006 IBM Corporation and Object Mentor. All rights reserved. This program and the accompanying materials are made available under the terms of the Eclipse Public License v1.0 which accompanies this distribution, and is available at http://www.eclipse.org/legal/epl-v10.html. Contributors: IBM Corporation and Object Mentor - initial implementation |